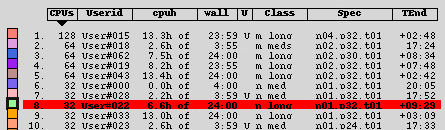
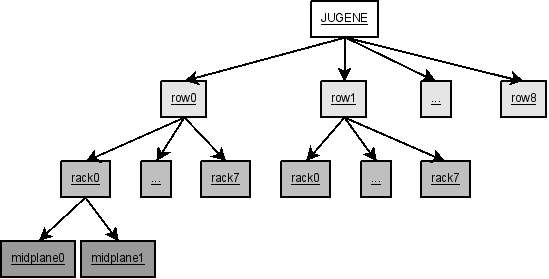
<nodedisplay title="JUGENE Nodedisplay" id="jugene">
<!-- definition of empty system -->
<scheme>
<el1 tagname="row" min="0" max="8" mask="R%01d">
<el2 tagname="rack" min="0" max="7" mask="%01d">
<el3 tagname="midplane" min="0" max="1" mask="-M%1d">
<el4 tagname="nodecard" min="0" max="15" mask="-N%02d">
<el5 tagname="computecard" min="4" max="35" mask="-C%02d">
<el6 tagname="core" min="0" max="3" mask="-%01d">
</el6>
</el5>
</el4>
</el3>
</el2>
</el1>
</scheme>
<!-- connection between physical elements and jobs -->
<data>
<el1 min="0" max="1" oid="job1" />
<el1 min="2" oid="job2">
<el2 list="3,5" oid="job3" />
</el1>
<el1 list="3,5" oid="job4">
<el2 list="0,7" oid="job5" />
</el1>
<el1 list="4" oid="job6">
<el2 list="6" oid="job6"/>
</el1>
<el1 min="6" oid="job9">
<el2 list="1,7" oid="job10" />
<el2 list="3,4,5" oid="job11" />
</el1>
<el1 list="7" oid="job12" >
<el2 min="0" max="3" oid="empty"/>
</el1>
<el1 list="8" oid="job13">
<el2 min="0" max="2" oid="job14" />
<el2 min="3" max="5" oid="job15" />
<el2 min="7" oid="empty">
<el3 list="1" oid="empty">
<el4 min="0" max="3" oid="job7" />
<el4 min="4" oid="job8" />
</el3>
</el2>
</el1>
</data>
</nodedisplay>
|

 Home | last change 20.08.2013 | copyright see
Home | last change 20.08.2013 | copyright see